Co to jest Edge Computing i dlaczego jest ważne?
Wyobraź sobie, że każda informacja, której potrzebujesz, jest na wyciągnięcie ręki. Brzmi jak marzenie, prawda? Właśnie tym zajmuje się Edge Computing.
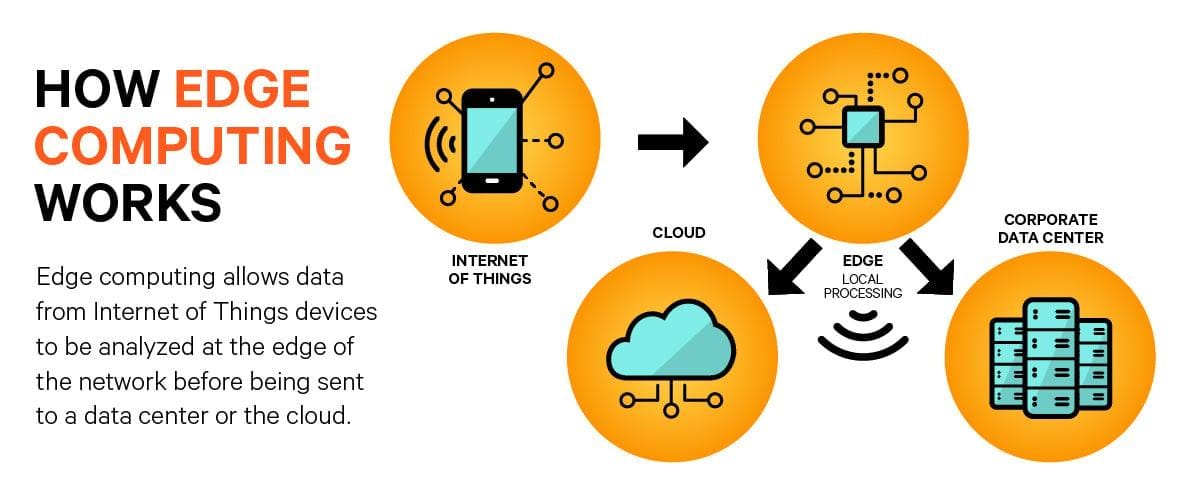
To podejście do przetwarzania danych przenosi moc obliczeniową bliżej miejsca, gdzie te dane są generowane, co pozwala na szybsze i bardziej efektywne działanie. Dzięki temu,w świecie,w którym każda sekunda ma znaczenie,mniejsze opóźnienia i lepsza wydajność stają się codziennością.
Ale jak dokładnie działa Edge Computing i dlaczego jest tak ważny w naszym życiu? Czy jesteś gotów odkryć jego tajemnice?
Spis treści
- Co wyróżnia Edge Computing od chmury?
- Jakie korzyści przynosi Edge Computing?
- Przykłady zastosowania Edge Computing w różnych branżach
- Jakie wyzwania niesie Edge Computing?
- FAQ
- Przyszłe perspektywy
Co wyróżnia Edge Computing od chmury?
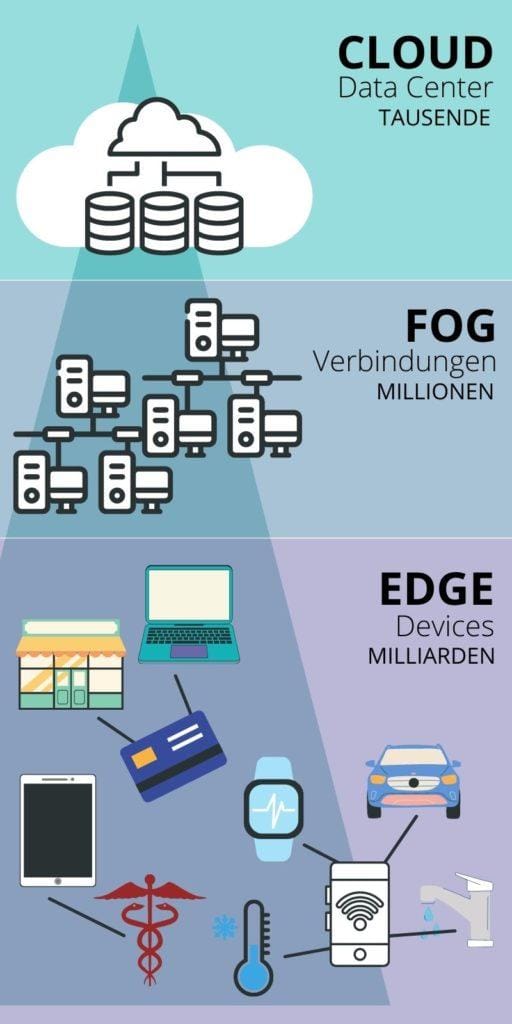
Edge Computing różni się od tradycyjnych rozwiązań chmurowych przede wszystkim poprzez lokalizację przetwarzania danych. W modelu chmurowym dane są przesyłane do centralnych serwerów, często znajdujących się daleko od miejsca ich generowania. W przeciwieństwie do tego, edge computing przetwarza dane bezpośrednio w lokalizacji ich powstania lub bardzo blisko niej. Dzięki temu możliwe jest znaczące zmniejszenie opóźnień,co ma kluczowe znaczenie w aplikacjach wymagających natychmiastowej reakcji,takich jak autonomiczne pojazdy czy systemy zarządzania ruchem miejskim.
Jeszcze jednym kluczowym różnicą między tymi dwoma podejściami jest sposób zarządzania danymi. W chmurze dane są zwykle przechowywane przez dłuższy czas,co może prowadzić do przeciążenia sieci i zwiększenia kosztów transferu danych.W edge computing, dane mogą być przetwarzane i analizowane na miejscu, a tylko niektóre z nich są przesyłane do chmury w celu długoterminowego przechowywania lub dalszej analizy. To nie tylko efektywniejsze, ale także bardziej oszczędne, ponieważ eliminuje zbędny ruch sieciowy.
Przykładem zastosowania edge computing może być inteligentna fabryka, w której maszyny są wyposażone w czujniki zbierające dane w czasie rzeczywistym. Dzięki temu mogą one na bieżąco dostosowywać swoje działanie, co zwiększa efektywność produkcji. W przypadku awarii, system może natychmiast zareagować, podejmując działania naprawcze, zanim problem stanie się poważny. To pokazuje, że edge computing nie tylko optymalizuje działanie urządzeń, ale także może przyczynić się do zwiększenia bezpieczeństwa.
Edge computing sprawdza się doskonale w aplikacjach związanych z Internetem Rzeczy (IoT), gdzie ogromna ilość danych jest generowana przez nasze codzienne urządzenia. W takich przypadkach kluczowe jest, aby zminimalizować opóźnienia oraz ograniczyć obciążenie sieci. Przykładami mogą być smart home, gdzie urządzenia inteligentne komunikują się ze sobą bez wysyłania wszystkich informacji do chmury, oraz systemy zarządzania miastami, które analizują dane na bieżąco, aby poprawić jakość życia mieszkańców.

Jakie korzyści przynosi Edge Computing?
Edge Computing przynosi wiele korzyści, które przekładają się na efektywność działania różnych systemów i aplikacji. Główną zaletą jest zminimalizowanie opóźnień w przesyłaniu danych. Dzięki przetwarzaniu informacji blisko miejsca ich pochodzenia, decyzje mogą być podejmowane na bieżąco. Na przykład, w samochodach autonomicznych czas reakcji jest kluczowy. Przesyłanie danych do centralnych serwerów w chmurze może prowadzić do niebezpiecznych opóźnień.Edge Computing umożliwia szybsze przetwarzanie, co zwiększa bezpieczeństwo i komfort użytkowników.
Inny istotny aspekt to oszczędność pasma sieciowego.W tradycyjnym modelu dane są przesyłane do chmury, co generuje znaczny ruch. W Edge Computing większość obliczeń odbywa się lokalnie, a tylko niezbędne informacje są wysyłane do chmury. Na przykład, w inteligentnych fabrykach urządzenia mogą analizować zgromadzone dane w czasie rzeczywistym, eliminując konieczność przesyłania wszystkich surowych danych. Taki model nie tylko ogranicza koszty transferu, ale również zmniejsza obciążenie sieci.
Ponadto, Edge Computing zwiększa prywatność i bezpieczeństwo danych. Gromadzenie i przetwarzanie informacji lokalnie pozwala na lepszą kontrolę nad danymi osobowymi. W dobie rosnącej liczby cyberzagrożeń, tego typu rozwiązania są kluczowe dla ochrony wrażliwych informacji. W przemyśle medycznym, na przykład, urządzenia monitorujące pacjentów mogą analizować dane bez konieczności przesyłania ich do chmury, co zmniejsza ryzyko ich przechwycenia przez osoby trzecie.
Wreszcie, Edge Computing wspiera różnorodność zastosowań w branżach takich jak przemysł, transport, czy handel. Systemy monitorowania w czasie rzeczywistym, automatyzacja procesów produkcyjnych czy inteligentne miasta są tylko kilkoma przykładami, gdzie ta technologia może znacznie poprawić efektywność. Dzięki mniejszym wymaganiom dotyczącym przepustowości,a także szybszej analizie danych,firmy mogą wprowadzać innowacyjne rozwiązania,które przyspieszają rozwój i zwiększają konkurencyjność na rynku.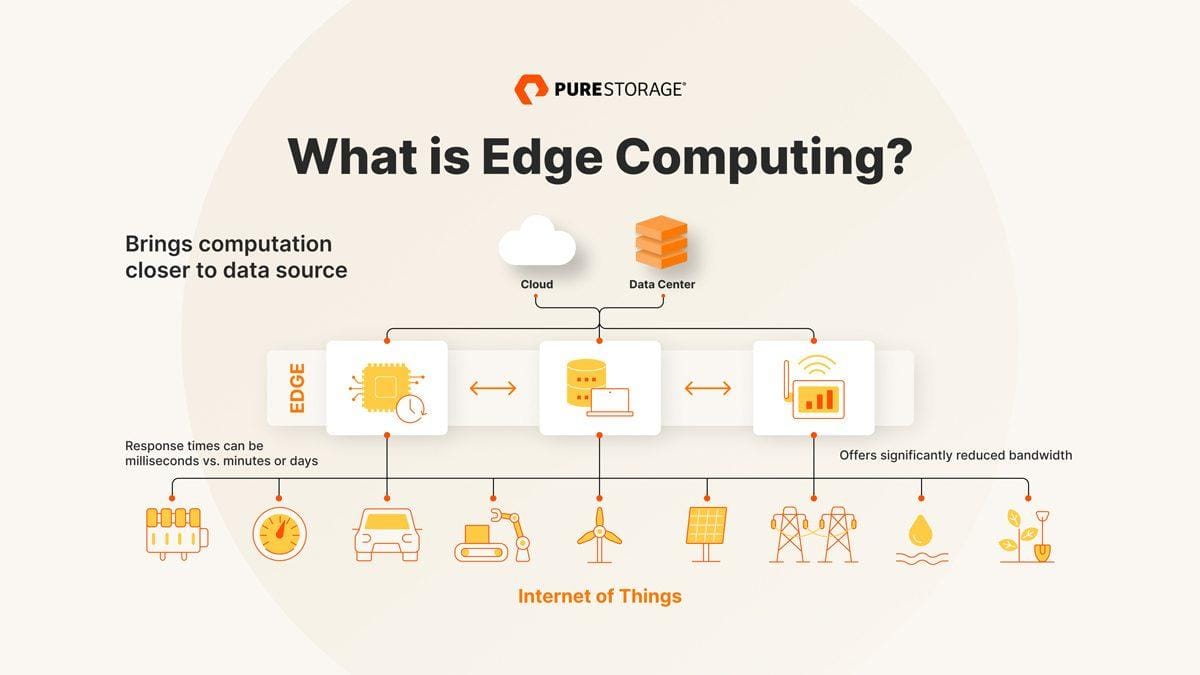
Przykłady zastosowania Edge Computing w różnych branżach
Edge Computing ma wiele zastosowań w różnych branżach, a jego zastosowanie przynosi realne korzyści. W sektorze transportowym, na przykład, technologia ta umożliwia śledzenie pojazdów w czasie rzeczywistym. Dzięki temu firmy logistyki mogą efektywniej zarządzać flotą oraz minimalizować opóźnienia. Przykładem jest firma transportowa, która zintegrowała czujniki w swoich samochodach, co pozwoliło na bieżące monitorowanie ich stanu technicznego, co z kolei zmniejszyło przestoje.
W ochronie zdrowia Edge Computing przyczynia się do szybszego przetwarzania danych pacjentów. W szpitalach, gdzie czas reakcji na sytuacje awaryjne jest kluczowy, lokalne analizy danych umożliwiają lekarzom szybsze podejmowanie decyzji. Urządzenia mobilne i noszone mogą błyskawicznie przesyłać dane o życiu pacjenta do systemów monitorujących,co znacząco zwiększa bezpieczeństwo pacjentów.
W branży przemysłowej, zastosowanie Edge Computing w automatyzacji produkcji również przyczynia się do optymalizacji procesów. W fabrykach, gdzie maszyny są wyposażone w sensory, mogą one na bieżąco analizować swoje parametry pracy. To pozwala na wczesne wykrywanie usterek, co z kolei zmniejsza koszty utrzymania maszyn. Przykładem może być zakład produkcyjny,który dzięki lokalnemu przetwarzaniu danych zmniejszył czas przestojów o 20%.
W sektorze detalicznym Edge Computing pozwala na personalizację doświadczeń zakupowych klientów. Systemy analizy danych w czasie rzeczywistym umożliwiają dostosowanie reklam do zachowań klientów w sklepie. Przykładowo, gdy użytkownik zbliża się do określonej półki, aplikacja mobilna może zaproponować zniżki na produkty, które go interesują. Taki zabieg zwiększa szansę na finalizację zakupu,co jest korzystne zarówno dla konsumentów,jak i sprzedawców.
Jakie wyzwania niesie Edge Computing?
Edge Computing, mimo swoich wielu zalet, stawia przed organizacjami szereg wyzwań. Bezpieczeństwo danych to kluczowy problem. Przechowywanie informacji bliżej źródła ich generowania oznacza, że muszą one być skutecznie chronione na wielu poziomach. W praktyce oznacza to konieczność zabezpieczenia urządzeń brzegowych oraz samej sieci, co może być skomplikowane i kosztowne.Przykładami mogą być ataki na nieautoryzowane urządzenia IoT, które są często mniej zabezpieczone niż tradycyjne serwery.
Wydajność systemu również stanowi istotne wyzwanie. Wprowadzenie wielu punktów obliczeniowych może prowadzić do problemów z zarządzaniem i synchronizacją danych. Skalowanie infrastruktury w obliczu rosnących potrzeb technologicznych wymaga przemyślanych inwestycji i strategii. Niezbędne jest również, aby organizacje posiadały odpowiednie kompetencje w zakresie zarządzania rozproszonymi systemami, co może być barierą dla mniejszych firm.
Przez lokalizację przetwarzania danych,Edge Computing stawia przed użytkownikami ograniczenia związane z regulacjami prawnymi. Wiele krajów ma różne przepisy dotyczące przechowywania danych, co oznacza, że firmy muszą dokładnie zrozumieć te różnice. Niewłaściwe zarządzanie danymi może prowadzić do kar finansowych oraz utraty zaufania klientów.
Na koniec, interoperacyjność różnych urządzeń i systemów jest kolejnym istotnym wyzwaniem. Wiele organizacji korzysta z różnorodnych rozwiązań technologicznych, co sprawia, że integracja różnych systemów staje się trudna. Przykładowo, trudno jest spiąć ze sobą urządzenia produkcyjne z systemami informatycznymi w biurze, co może prowadzić do niskiej efektywności i trudności w analizie danych.
FAQ
Co to jest Edge Computing?
Edge Computing to model przetwarzania, w którym dane są przetwarzane w pobliżu źródła ich generacji, a nie w scentralizowanych chmurach. Pozwala to na szybszą analizę informacji oraz zmniejsza opóźnienia, co jest kluczowe w sytuacjach wymagających natychmiastowej reakcji, na przykład w przypadku pojazdów autonomicznych.
Jakie są zalety Edge Computing?
Jedną z głównych zalet Edge Computing jest poprawa wydajności.Dzięki przetwarzaniu danych lokalnie, zmniejsza się czas potrzebny na ich transfer do chmury i z powrotem. Dodatkowo,umożliwia to zwiększenie bezpieczeństwa,ponieważ wrażliwe dane nie muszą opuszczać lokalnych urządzeń.
Gdzie znajduje zastosowanie Edge Computing?
Edge Computing znajduje zastosowanie w wielu branżach, takich jak przemysł, zdrowie, czy smart cities.Przykłady obejmują zastosowania w monitoringu wideo, gdzie dane są analizowane w czasie rzeczywistym, oraz w produkcji, gdzie pozwala na optymalizację procesów i minimalizację przestojów.
Czy Edge Computing wpływa na koszty operacyjne?
Tak, wdrożenie Edge Computing może przyczynić się do redukcji kosztów operacyjnych. Przetwarzanie danych bliżej źródła zmniejsza potrzebę przesyłania dużych ilości danych do chmury, co może prowadzić do oszczędności na kosztach transferu i przechowywania danych.
Jakie są wyzwania związane z Edge Computing?
Jednym z głównych wyzwań Edge Computing jest zarządzanie rozproszonymi zasobami. Wymaga to zaawansowanych strategii zarządzania, aby zapewnić płynność operacji i bezpieczeństwo danych. Dodatkowo, konieczne jest odpowiednie zainwestowanie w infrastrukturę, aby wspierać lokalne przetwarzanie.
Przyszłe perspektywy
Edge computing to nowoczesne podejście do przetwarzania danych, przypominające jadłodajnię, która serwuje świeżo przygotowane dania blisko swoich gości, a nie centralny catering z daleka. Dzięki przeniesieniu obliczeń bliżej źródeł danych, technologia ta pozwala na szybsze reakcje i zwiększa efektywność sieci, co jest kluczowe w dobie eksplozji różnych technologii. Jak wiele jeszcze możemy zyskać, gdy nasze dane będą miały „smak świeżości”?